
hamlet-story
HADOOP - [개념] 하둡에 대해서 알아보자 본문
2023년도를 기준으로 간단하게 Hadoop 2.0 이후 내용을 조사한 내용에 대해서 정리 해볼려고 합니다.
따라서 혹여 잘못된 부분이 있을 경우 답글 남겨주시면 감사하겠습니다.
설명을 아래와 같이 이루어 집니다.
1. Hadoop HDFS
2. Hadoop MapReduce
3. Hadoop Yarn
History
데이터의 종류는 크게 정형 데이터 (Structured data) 와 비정형 데이터 (Unstructured data) 로 존재합니다.
물론, 반정형 데이터 (Semi-structured data) 형식도 존재합니다. 대표적으로 JSON (JavaScript Object Notation) 이 존재 하죠.
하지만 지금은 정형과 비정형에 대해서만 알아보겠습니다.
Structured data
구조화된 데이터라고 합니다. 열과 행으로 데이터를 표현하고 있기 때문에 테이블 형식으로 표현을 할 수 있게 되며, 이를 통해서 관계형 데이터 베이스가 생기게 되고, 정형화된 수많은 데이터 들을 처리할 수가 있게 됩니다.
즉, 정해진 규칙에 맞게 데이터들을 관리하고 있기 때문에 수치 만으로 의미 파악이 쉬운 장점이 있습니다.
하지만, 정해진 규칙 (열, 행) 이 있다면 위 규칙을 지키지 못하는 데이터들 (소리, 사진) 도 있기 때문에 테이블 형식으로 표현하지 못하는 경우가 생기게 됩니다.
그래서 생기게 된것이 비정형 데이터라는 개념 입니다.
Unstructured data
정형 데이터가 규칙이 있는 구조화된 데이터라면, 이는 정의된 규칙이 없는 정보 라고 할 수 있습니다.
크게 보면 비디오, 오디오 등이 있습니다.
Hadoop 을 설명하는데 위의 개념은 왜 필요한 것일까요?
이유는 세상이 디지털화가 되기 이전 시절에서 확인 할 수 있습니다.
이때는 상대적으로 느린 속도로 아주 적은 양의 데이터가 생성이 되었고, 모든 데이터는 대부분 문서였으며, 행 과 열의 형태로 정리가 되었기 때문에 저장과 처리에 대한 문제가 많이 생겨나지가 않았습니다.
하지만 인터넷이 발전하게 되면서 수많은 반정형 비정형 데이터가 생기게 되었고,
이를 저장하거나 처리 할만한 방안이 필요하게 되었습니다.
때문에 생겨난 수많은 방안 들 중에 Hadoop 나오게 된 것이죠.
Hadoop HDFS
Hadoop은 앞서 설명한 비정형, 반정형 과 같은 빅데이터 들은 한 컴퓨터에 저장하는 것이 불가능 하므로 데이터를 여러 컴퓨터에 분산되어 Block에 저장 하는 FileSystem 을 개발하였습니다.
이를 HDFS (Hadoop Distributed FileSystem) 하둡 분산형 파일 시스템 이라고 말합니다.
HDFS system design (Architecture)

HDFS 는 Master 역할을 하는 NameNode 서버 한대와, Slave 역할을 하는 DataNode 서버 여러대로 구성됩니다.
NameNode 는 HDFS 의 모든 MetaData(Block 들이 저장되는 Directory Name, File Name 등)을 관리하고, HDFS Client 가 이를 이용하여 저장된 파일에 접근할 수 있습니다.
Hadoop Application 은 DFS (Distribute File System) 에 파일을 저장하거나, 저장된 파일을 읽기 위해 HDFS Client 를 사용하며, NameNode는 DataNode 가 정상 동작하는지 확인합니다.
HDFS Client 는 NameNode에 접속해서 원하는 파일이 저장된 Block 의 위치를 확인하고, 해당 Block 이 저장된 DataNode 에서 직접 데이터를 조회 합니다.
그러면, NameNode 에서는 데이터를 어떻게 Block 형태로 나눌까요?
NameNode Split Blocks
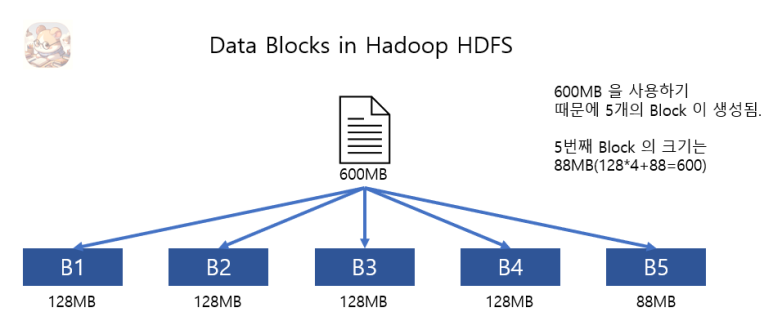
일반적으로 물리적인 디스크는 Block이라는 개념을 이용합니다. Block은 한번에 읽고 쓸 수 있는 데이터의 최대량을 의미합니다.
Hadoop 에선 Block 의 크기를 128MB 로 지정하였습니다.
왜 이렇게 크게 사용을 할까요?
이유는 다음과 같습니다.
1. 탐색 비용을 최소화 하기 위해
2. 블록이 작으면 Hadoop HDFS 에 블록이 너무 많아 저장할 MetaData 가 너무 많아지기 때문
즉, 큰 크기의 블록의 경우 디스크에서 데이터를 전송하는 데 걸리는 시간이 Block을 시작하는데 걸리는 시간에 비해 시간이 길어질 수 있으며, 엄청난 수의 MetaData 를 관리하면 OverHead 가 발생하고 Network Treffic 이 발생하게 됩니다.
그러면 궁금한 점이 생기게 될 것 입니다.
만약 누어진 Block 들을 각각의 DataNode 즉 각각의 서버에 저장하게 된다면 그 서버가 다운되었을때의 데이터 손실은 어떻게 처리해 주는 것이지?
그렇기 때문에 각 나누어진 Block 들은 각각 3개씩 복제 하여 데이터를 저장합니다.
이렇게 되면, 한개의 서버가 다운되더라도 다른 서버에서도 그 Block 을 저장하고 있기 때문에 손실에 대한 어느정도 방지를 할 수 있게 됩니다. 그리고 이를 Replication Method 라고 부릅니다.
Hadoop MapReduce
데이터를 관리하기 위한 방안으로 HDFS 을 고안하였지만 다음으로 데이터를 효율적으로 처리 하기 위한 방안 이 필요하였습니다.
전통적으로 활용 되었던 데이터 처리 방식은 시간도 많이 걸리고 대용량 데이터를 처리할 때 비효율 적일 것입니다.
그래서 효율적으로 처리 할 수 있는 방안을 고안한 것이 바로 MapReduce 입니다.
MapReduce system design (Architecture)
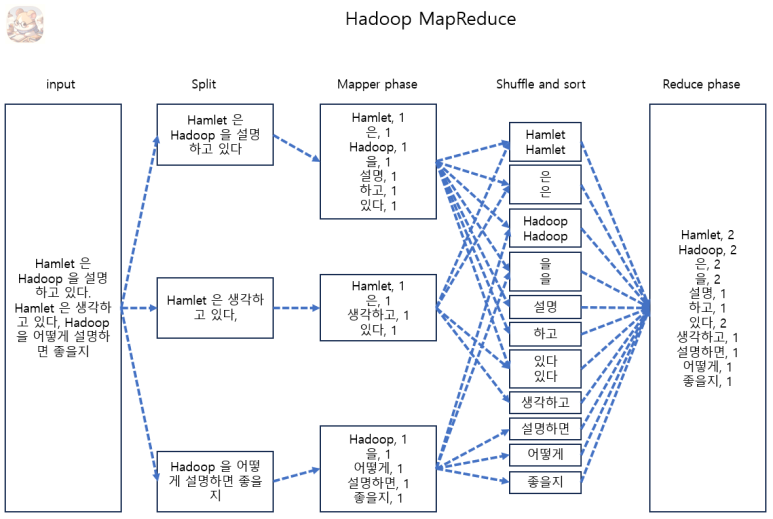
MapReduce 가 동작하는 방식으로는 크게 Input, Split, Mapper phase, Shuffle and sort, Reduce phase 로 볼 수 있습니다.
Input 에서 전체 데이터들을 받고
Split 에서 전체 데이터를 적당하게 자르고
Mapper phase 에서 Key Value 형식으로 나누고
Shuffle and sort 에서 Key Value 값을 그룹화 하고, 정렬하여
최종적으로 Reduce phase 에서 그룹화된 데이터를 정리합니다.
이러한 과정을 통해서 로드 밸런싱을 개선하고 상당한 시간을 절약할 수 있게 됩니다.
이제 Hadoop 을 구성하기 위한 간단한 개념을 만들었기 때문에 Cluster 에서 실행할 수 있어야 합니다.
이는 RAM 네트워크 대역폭 및 CPU 와 같은 Resource 세트 들의 도움으로 수행됩니다.
여러작업이 Hadoop 에서 수행이 될 것이기 때문에 이러한 Resource 을 효율적으로 관리하기 위한 방안이 필요하게 되었습니다.
자세한 내용은 여기를 참고해 주세요.
그래서 또 생겨난 것이 Hadoop Yarn 입니다.
Hadoop YARN
YARN (Yet Another Resource Megotiator) 은 Resource Manager, Node manager, Application Master, Containers 로 구성이 됩니다.
Resource Manager 은 Resource 를 할당하는 Container 로 구성이 됩니다.
Node Manager 은 Node 를 처리하고 Node 의 Resource 사용량을 모니터링 합니다.
Containers 는 물리적 Reousrce 의 모음 입니다.
시간 관계상 더 자세한 내용을 여기를 참조 해주세요. (잘 설명 해주셔요)
YARN system design (Architecture)
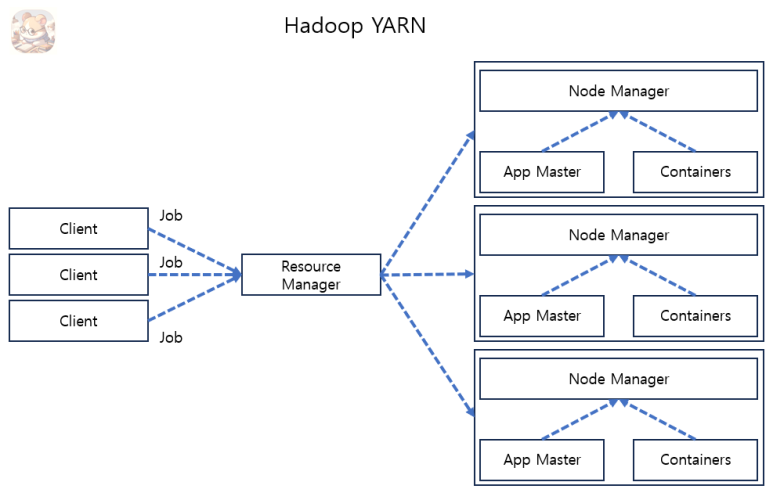
전체적인 System 동작 과정은 아래와 같습니다.
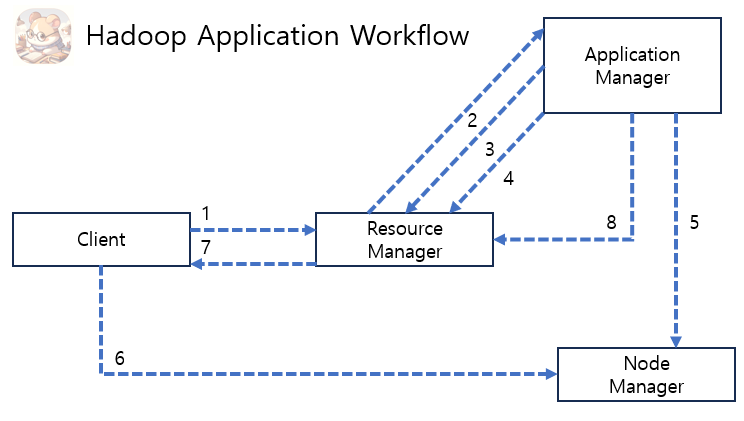
1. Client 가 요청을 합니다.
2. Resource manager 는 Application Manager 를 시작하기 위해 Container 을 할당합니다.
3. Application Manager 는 Resource Manager 에 자신을 등록 합니다.
4. Application Manager 는 Resource Manager 의 Container 을 확인 합니다.
5. Application Manager 는 Node Manager 에게 Container 을 시작하도록 요청 합니다.
6. Application Code 는 Container 에서 실행됩니다.
7. Client 는 Resource Manager / Application Manager 에 접속하여 Application 상태를 모니터링 합니다.
8. 처리가 완료되면 Application Manager 는 Resource Manager 에 등록을 취소 합니다.
결론
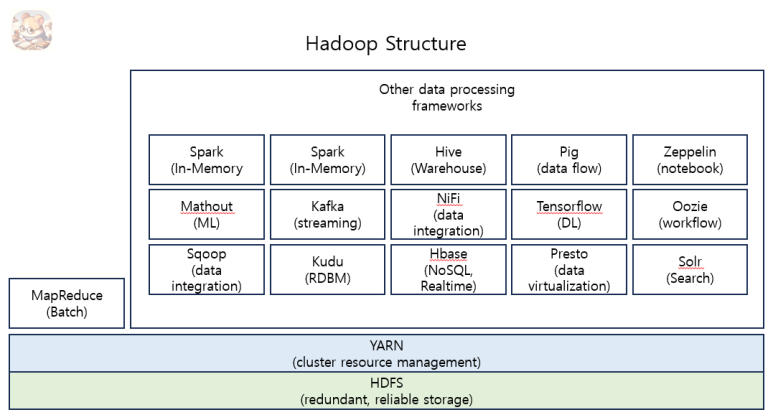
정리를 해보겠습니다.
YARN : 작업 Scheduling 및 Resource 관리
HDFS : 높은 처리량을 보이는 FileSystem
MapReduce : 크기가 큰 데이터 세트를 병렬 처리하기 위한 Frame Work
지금까지 설명한 내용 말고도 Hadoop 처리를 도와주는 여러 Open Source Frame work 들이 있기 때문에 더욱더 높은 효율성을 보여줍니다.
여기까지 Hadoop 에 대한 정리를 마치도록 하겠습니다.
참고
https://www.geeksforgeeks.org/hadoop-yarn-architecture/
https://hmdev.vercel.app/Yarn%EC%9D%B4%EB%9E%80
https://www.youtube.com/watch?v=uEtbE7WuxdM